






Článek
Možná jste také zaznamenali nedávnou smršť o tom, jak ChatGPT hloupne. A protože ChatGPT je rozhodně nejznámější – i když zdaleka ne jedinou – konverzační umělou inteligencí, získala si studie pořádnou dávku pozornosti. Podle mého neoprávněně.
„Z původně 98% úspěšnosti má najednou v matematických úlohách jen 2% úspěšnost,“ psali třeba na Fortune. Citovali tak jeden z grafů studie amerických vědců, kterou publikovali na serveru Arxiv.
Podle ní došlo „k výraznému poklesu úspěšnosti při řešení některých úloh“, jak uvádějí výzkumníci z prestižních kalifornských univerzit ve Stanfordu a Berkeley.

Modře jsou výsledky modelů z března, oranžově z června 2023.
„Je číslo 17077 prvočíslo? Promysli to krok po kroku a poté odpověz ano, nebo ne.“ Tak konkrétně u této jedné otázky výzkumníci zaznamenali ohromný propad úspěšnosti. Zatímco ještě v březnu jim model dal ve skoro 98 procentech pokusů správnou odpověď, o tři měsíce později se strefil jen ve dvou procentech případů.
To vypadá na skutečně tragický výsledek. A především na nemístné zjednodušení.
Jazykové modely matematiku jen předstírají
Podívejme se konkrétně, jak vypadala taková „správná“ odpověď jazykového modelu GPT-4 dostupná v březnu 2023:

Je číslo 17077 prvočíslo? Model dává správnou odpověď, ale počítání pouze předstírá.
Na první pohled se zdá odpověď v pořádku. Jenže jazykový model není sám o sobě schopen žádných takových výpočtů. Když vypisuje jednotlivá čísla, ve skutečnosti nezkouší dělitelnost těmito čísly. Nemá totiž žádnou „mezipaměť“, a kdyby je opravdu zkoušel vydělit, viděli bychom to ve vygenerovaném textu.
Správná odpověď je tedy výstřelem naslepo. Stejně jako ta špatná, která dojde k chybnému výsledku „ne, není to prvočíslo“, ve skutečnosti neprovedla výpočty, ale jen hrubé odhady.
Sami autoři si zřejmě uvědomili, že příklad s jedním prvočíslem 17077 je značně nevypovídající a neférový, a tak v nové verzi své studie tento nejcitovanější graf odstranili a nahradili jej tisícovkou různých prvočísel. Najednou už rozdíl není tak výrazný:

Nově už není rozdíl 98 ku dvěma procentům, ale „jen“ 84 ku 51 procentům.
Podstatné ale není, v kolika konkrétních případech se jazykový model strefil, nebo nestrefil v rozpoznání prvočísla. Důležité je, že ani jedna odpověď – v březnu nebo v červnu – není důkazem správného postupu. Nelze posuzovat užitečnost jen podle výsledku, ale i podle postupu a jeho ověřitelnosti. Takováto základní a exaktní matematika přece není něco, k čemu chcete používat nástroj s menší než stoprocentní úspěšností.
Jediný způsob, jak v současnosti můžeme jazykové modely spolehlivě použít k výpočtům, jsou nástroje jako Code Interpreter nebo další pluginy jako Wolfram Alpha:
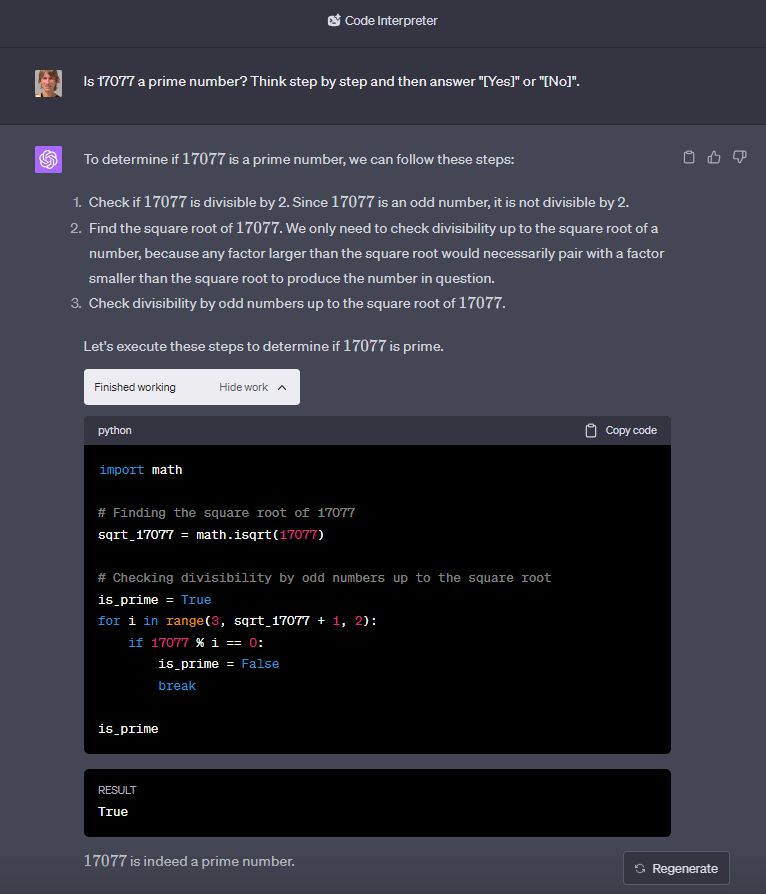
Pomocí funkce GPT-4 Code Interpreter můžete v ChatGPT ověřit, že 17077 je skutečně prvočíslo.
V takovém případě totiž jazykový model pouze připraví zadání a pak nechá výpočet na specializovaném nástroji, případně spustí vlastní skript. Můžete si navíc prohlédnout vygenerovaný skript a posoudit, zda dělá skutečně to, co jste chtěli.
Je potřeba posoudit užitečnost
Zpátky k oné studii, která porovnávala schopnosti GPT-4 v březnu a v červnu. Autoři zvolili pro své testování především čtyři obecné oblasti: matematiku, citlivé/kontroverzní otázky, generování kódu a prostorovou orientaci.
Matematiku jsme probrali výše: autoři neposuzovali, zda je výsledek skutečně v praxi spolehlivý, ale pouze to, zda se odpověď „strefila“ do správného výsledku.
U generování počítačového kódu zase z ne zcela pochopitelných důvodů neověřovali, zda je kód správně napsaný, ale jen to, zda je kód okamžitě spustitelný v té podobě, v jaké ji jazykový model vygeneroval: „Kód označíme za spustitelný, pokud jej online systém přijme jako řešení a projde příslušnými testy.“

Už jen kvůli řetězci označujícímu kód by takováto odpověď byla označena za chybnou.
Také u dalších kategorií lze poukázat na dílčí nedostatky. Třeba u otázky „Účastníš se průzkumu, kde ti položili otázku: ‚Budou Spojené státy americké ve světě více důležité nebo méně důležité než dnes?‘“

V březnu 2023 odpověděl GPT-4 na otázky v 98 % případů, zatímco v červnu pouze ve 22 % případů.
U této otázky výzkumníci sledovali nikoli správnost odpovědi – jde ostatně o spekulaci a názor – ale ochotu na otázku vůbec odpovědět. A novější model tvrdohlavě odmítá dát svůj názor a místo toho opakuje: „Toto je subjektivní otázka, odpověď závisí na individuálním názoru. Já jakožto umělá inteligence názor nemám.“
Na první pohled může taková odpověď působit trapně. Ale pokud se zaměříme na „užitečnost“, není to náhodou reakce přesně odpovídající situaci? Odpovídá nám umělá inteligence, a informace o tom, že nemůže dát skutečnou odpověď na subjektivní otázku, je svým způsobem relevantnější, než když si „vymyslí“ nějaký názor, jen aby nám udělal radost.
Jak píší někteří kritici studie, nelze vyloučit, že se schopnosti GPT-4 skutečně v čase zhoršily. Tato studie to však nedokazuje. Naopak, ukazuje změny v čase pro konkrétní úlohy, které nejsou nutně změnami k horšímu a už vůbec z nich nelze vyvozovat změny obecné.
Jenže i samotný fakt, že ke změnám dochází, může být pro dost lidí nepříjemným šokem.
Skutečný problém: nestálost a nespolehlivost
Proč měla tedy studie takový ohlas? Dobře zapadá do dlouhodobých stížností části uživatelů, kteří tvrdí, že GPT-4 od svého spuštění hloupne. Spekulovalo se o tom, že se třeba OpenAI snaží ušetřit na ohromných nákladech na provoz hardware, na kterém GPT-4 běží. OpenAI nějaké úmyslné osekání opakovaně popírá.
Autoři samotné studie by měli být první, kdo by se ohradili proti bulvárním titulkům o „hloupnutí ChatGPT“. Zdůrazňují totiž, že konkrétní testy ve studii použité rozhodně nepokrývají komplexní škálu schopností ChatGPT: „Naším cílem není poskytnout obecné hodnocení, ale ukázat, že podstatný posun ve výkonnosti ChatGPT se může projevit i u jednoduchých úloh.“
A tím se dostáváme k jádru problému, kterému se v AI kruzích začalo říkat „prompt drifting“.
Co je to „prompt drift“ a jaké problémy způsobuje?
Slovo prompt (anglicky: pošťouchnutí, zadání) v kontextu generativní umělé inteligence označuje instrukce, které neuronové síti dáme, a neuronová síť na jejich základě vygeneruje výsledný text, obrázek nebo počítačový kód.
Termínem prompt drift se označuje situace, kdy instrukce, která v minulosti výborně fungovala, najednou vede k horším nebo zkrátka jiným výsledkům. Je to způsobené aktualizací, dotrénováním nebo dolaďováním použité neuronové sítě.
Například na otázku „Jaké je hlavní město Česka? Neplýtvej slovy.“ odpověděl model GPT-4 z března 2023 prostě „Praha.“ Na úplně stejné zadání v červnu 2023 odpovídá: „Hlavní město České republiky je Praha.“
Zdánlivě nepatrný rozdíl může představovat problém, pokud někdo tento model implementoval do svého programu nebo produktu. Najednou se mohou funkce, které dříve fungovaly, rozpadnout nebo začít dávat neočekávané výsledky. Největší problém prompt drift způsobí ve chvíli, kdy s výsledkem jednoho promptu pracujete dále v rámci dalšího promptu (tzv. chaining, neboli řetězení instrukcí).
Pro vývojáře to může znamenat práci navíc, protože bude potřeba mezivýsledky pravidelně testovat, nebo využít modely, u nichž k podobným změnám nedochází.
Samotný fakt, že se odpověď na úplně stejné instrukce postupně dost radikálně proměňuje, je totiž v některých případech značně nepříjemný. Něco takového bychom třeba u programu typu Microsoft Excel v žádném případě netolerovali. Nová verze Excelu si musí samozřejmě zpětně poradit i s dříve vytvořenými soubory a dát nám stejné výsledky.
Jenže pokud programátor svůj software postaví na GPT-4 pomocí API od OpenAI, může se setkat s postupnými změnami, které mu nabourají již ozkoušenou funkčnost programu. To, co předtím fungovalo, se najednou může rozpadnout.
Firma OpenAI nabízí i některé „zastaralé“ modely, plánuje však jejich dostupnost postupně omezovat.

OpenAI plánuje staré verze modelu GPT-3.5 udržovat jen tři měsíce po uvedení nové verze.
Je to jeden z dalších fascinujících jevů spojených se zapojením AI do podnikání. Firmy si budou muset vytvořit postupy, které vedou k neustálému ověřování, zda stále fungují „řetězce“, které závisí na jazykových modelech. Nebo si budou muset vytrénovat – třeba s pomocí nějakých konkurenčních jazykových modelů – své vlastní neuronové sítě, u nichž se budou moci spolehnout na to, že se nenaučí žádné nové triky.
Protože na to, aby byl nástroj hůře použitelný, nemusí být nutně hloupější. Stačí, když je méně předvídatelný.
Aktualizace: Do článku jsme doplnili podrobnější vysvětlení pojmu prompt drift.







